PySpark is the Python application programming interface for Apache Spark i.e. an open-source framework and collection of tools for large-scale, real-time distributed computing.
PySpark is essentially a Python API for Spark, and it was developed to facilitate the interaction between Apache Spark and Python. Furthermore, it also facilitates Python programming and Apache Spark interfaces with Resilient Distributed Datasets (RDDs).
Given these significant advantages, CodeInterview now features the support of PySpark to enhance the interview process for the interviewers and the candidates. This new addition enables the use of Apache Spark in coding and technical interviews, making the process more interesting.
Discover the online PySpark IDE for your interviews!
What is Pyspark Used for?
The majority of data scientists and researchers are proficient with Python, which they use to execute machine learning algorithms. PySpark enables them to use a familiar language on large-scale distributed datasets. Apache Spark is also compatible with the data science programming language R.
It supports a wide range of data formats and sources, including standard structured data as well as semi-structured and unstructured data such as JSON and CSV files. Furthermore, it enables complicated data transformations, aggregations, and joins, allowing users to manipulate data with greater accuracy.

Launching PySpark Project In CodeInterview
Login to CodeInterview and go to the interview environment. Afterwards, navigate to the Language Switch panel. This panel appears at the bottom as a dropdown menu. In the Language Switch panel, you will find the PySpark project as shown below:
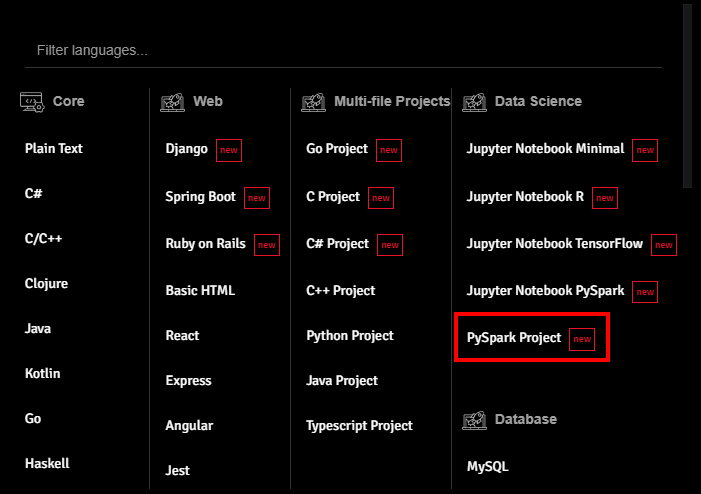
Once you have selected the PySpark project, you will be navigated to the new screen that contains the code editor, interactive shell, and an output panel as shown below. Here, you can seamlessly begin conducting your online coding interview.
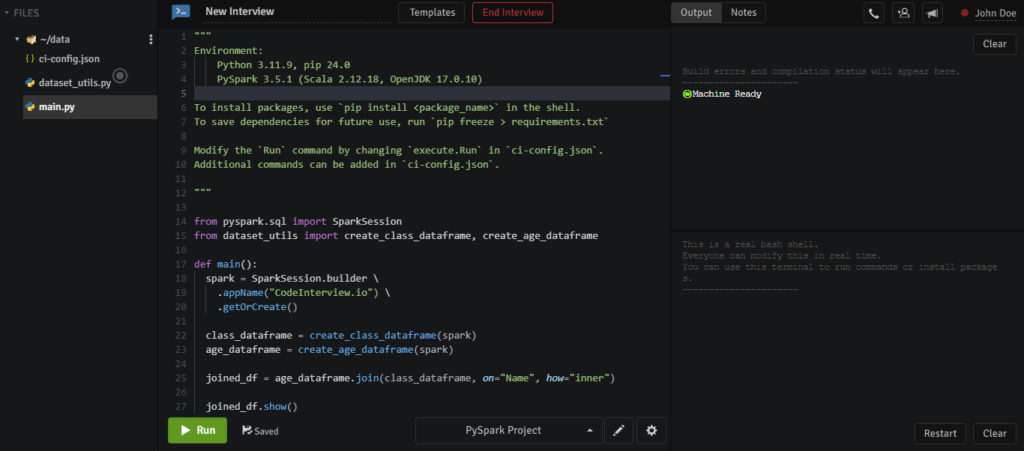
Working With Shell
This online PySpark IDE comes with an interactive shell command that allows users to explore, test examples, and analyse data from the command line. Spark has separate shells for Scala, Python, R, and Java.
During the interview, candidates can use the interactive shell to demonstrate their ability to build and execute code directly, showcasing their knowledge of data manipulation, querying, and analysis. This improves the candidate’s engagement with coding assessments.
The shell command also allows interviewers and candidates to install packages for additional functionalities, such as advanced data processing techniques, machine learning models, or data source connections improving the overall interview procedure.
Create Engaging Templates
CodeInterview allows interviewers to create engaging templates to conduct interviews with PySpark. Interviewers can create interview templates that deal with any specific role or position.
With the feature of creating templates, interviewers can easily incorporate real-world questions and scenarios in their assessments, assuring a thorough examination of the skills of the candidates.
How Does PySpark Environment Help in Conducting Interviews?
PySpark appears to be extremely useful for conducting interviews, particularly technical and coding interviews. Here are the primary ways PySpark can help:
- Integration of PySpark with machine learning libraries such as MLlib enables the interviewer to evaluate the ability of the candidate to create and deploy machine learning models. Interview tasks may involve training models, reviewing performance indicators, and optimising algorithms for distributed datasets.
- Interviewer can evaluate whether the candidate knows how to use the DataFrame API to simplify difficult operations like aggregation using PySpark groupBy or column manipulations with PySpark withColumn.
- PySpark integrates easily with tools like Hadoop and Kafka, demonstrating the ability of candidates to work within complex data ecosystems. Additionally, candidates can use functions like the PySpark Union function and PySpark Collect function to merge datasets and gather distributed data locally, respectively.
- PySpark pivot function assists interviewers in assessing candidates for dynamic data summarising and visualisation work. Whereas, candidates can demonstrate their ability to pivot data for personalised perspectives and aggregations.
- In order to evaluate whether a candidate is good with text analytics, data cleansing, and pattern recognition, the PySpark substring function helps interviewers with it efficiently.
- Compatibility of PySpark with workflow orchestration technologies allows candidates to demonstrate their ability to develop and manage complicated data. This may include creating DAGs, scheduling tasks, and analysing pipeline execution.
- Interviewers can examine the understanding of candidates to optimise performance by testing their understanding of Spark SQL optimisation techniques including partitioning, caching, and broadcast joins.
Start Working With PySpark Today!
Join CodeInterview today and start your interviewing process with ease. Our platform provides effective tools and features for conducting technical interviews in PySpark, allowing you to discover top talent effectively. Along with Pyspark, you can also explore our Python coding interview questions to further enhance your assessments.
Sign up to CodeInterview and explore the new opportunities now!